TL;DR - Claude Code có Stop hook chặn agent hoàn thành cho đến khi verification pass. Kết hợp với PostToolUse feedback injection, bạn có thể xây verification loop 3 lớp (syntax, intent, regression) trong 20 phút. Nhảy đến setup đầy đủ →
📊 Bài này xây dựng:
- Hệ thống verification 3 lớp dùng 2 hook events và 3 handler types
- Stop hook copy-paste sẵn với anti-loop protection (
stop_hook_active)- Config
.claude/settings.jsonđầy đủ kết hợp cả 3 lớp- Phân tích ROI: verification tốn tokens, nhưng bỏ qua nó tốn 7 giờ/tuần
Hai cách setup hook. Cùng một phiên Claude Code. Kết quả khác nhau hoàn toàn:
# Cái mà đa số dev có: formatting hook# PostToolUse: chạy prettier sau khi edit filejq -r '.tool_input.file_path' | xargs npx prettier --write
# Cái bài này xây dựng: verification loop# PostToolUse: kiểm tra syntax trên mỗi file thay đổi# Stop: chặn hoàn thành cho đến khi tests pass + intent verified# Kết quả: agent không thể nói "xong" khi chưa thực sự xongSetup đầu tiên bắt lỗi formatting. Setup thứ hai bắt lỗi logic, yêu cầu thiếu, và tests hỏng trước khi agent tuyên bố đã xong.
PreCompletionChecklistMiddleware của LangChain là ví dụ được ghi nhận nhiều nhất về pattern này. Nó góp phần vào mức tăng 13.7 điểm benchmark chỉ từ harness changes. Bài này xây dựng phiên bản tương đương cho Claude Code bằng hooks.
”Verification” thực sự nghĩa là gì với AI coding agent?
Verification là kiểm tra output của agent có khớp với intent của task hay không, chứ không chỉ là code có compile được. Chỉ 3% developer báo rằng họ tin tưởng cao vào code AI tạo ra (Qodo, State of AI Code Quality, 2025). Đa số dev chỉ dừng ở mức syntax check (lint, format, type-check). Verification cho production cần thêm hai lớp nữa.
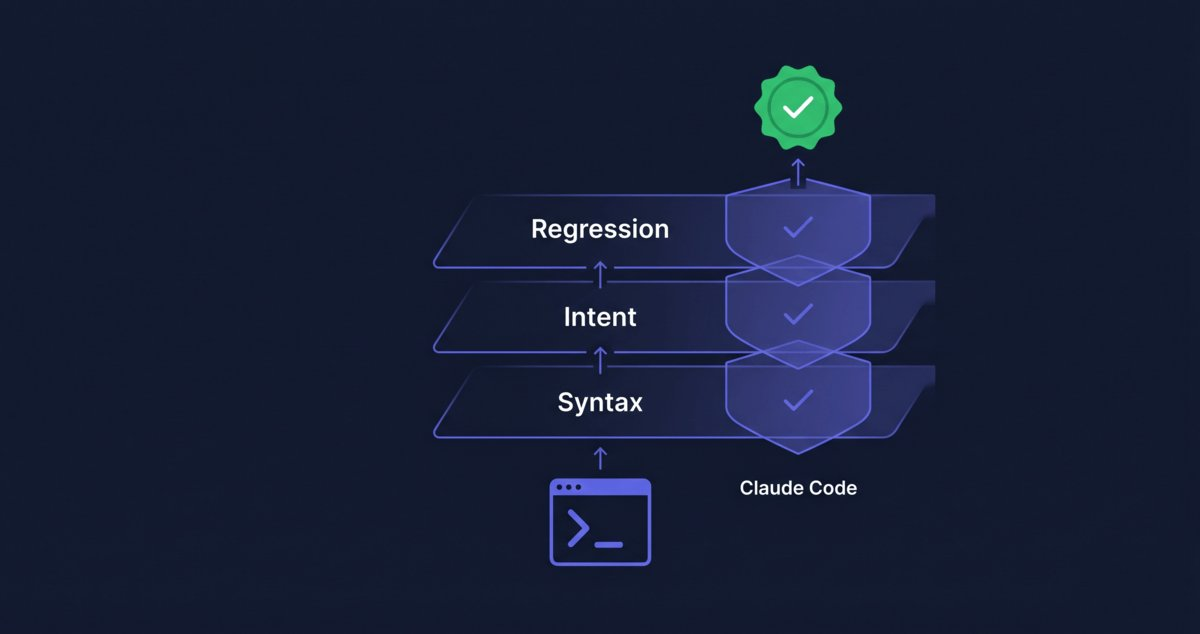
Ba lớp verification, mỗi lớp bắt một loại lỗi khác nhau:
| Lớp | Kiểm tra | Bắt được | Bỏ sót | Hook |
|---|---|---|---|---|
| 1. Syntax | Code compile, format đúng | Typos, type errors | Logic bugs | PostToolUse command |
| 2. Intent | Output khớp với request | Sai hướng, thiếu feature | Regression | Stop prompt/agent |
| 3. Regression | Tests cũ vẫn pass | Chức năng cũ bị hỏng | Yêu cầu chưa có test | Stop command |
“Chạy tests” chỉ cover Layer 3. Tests xác minh những gì bạn đã viết test, không phải những gì bạn yêu cầu agent làm. Nếu bạn yêu cầu Claude thêm pagination mà nó lại thêm sorting, mọi test vẫn pass. Layer 2 bắt được cái đó.
Hệ thống Honk của Spotify chứng minh điều này ở quy mô lớn: 1,500+ PR được merge qua verification loops, xử lý khoảng 50% tổng số PR tự động (Spotify Engineering, Dec 2025). Lựa chọn thiết kế quan trọng của họ: agent không biết verification hoạt động như thế nào. Nó chỉ nhận pass/fail feedback. Sự tách biệt này giữ agent tập trung vào task.
Stop hook của Claude Code hoạt động như thế nào?
Stop hook chạy mỗi khi Claude kết thúc phản hồi. Exit code 2 chặn Claude dừng lại và bắt buộc nó tiếp tục làm việc. Cơ chế đơn giản này ngăn agent nói “xong” khi chưa xong (Claude Code docs). Stop hook hỗ trợ 4 loại handler. Để so sánh chi tiết, xem Hook Decision Guide.
Đây là phần quan trọng mà hầu hết các tutorial bỏ qua: trường stop_hook_active.
#!/bin/bashINPUT=$(cat)
# QUAN TRỌNG: ngăn vòng lặp verification vô hạn# Khi true, Claude đang ở trạng thái forced-continuationif [ "$(echo "$INPUT" | jq -r '.stop_hook_active')" = "true" ]; then exit 0 # Cho Claude dừng, đừng loop mãifi
# Chạy tests, chặn stop nếu tests failnpm test 2>&1 || { echo "Tests đang fail. Sửa trước khi hoàn thành." >&2 exit 2}
exit 0Không kiểm tra stop_hook_active, hook sẽ chặn mỗi lần agent cố dừng. Claude sửa tests, cố dừng, bị chặn, sửa tiếp, cố dừng, bị chặn. Loop vô hạn. Luôn kiểm tra trường này.
Stop hook nhận JSON đầu vào như sau:
{ "session_id": "abc123", "transcript_path": "/path/to/transcript.jsonl", "cwd": "/your/project", "hook_event_name": "Stop", "stop_hook_active": false}Hai cách gửi feedback về cho model:
- Exit 2 + stderr: Nội dung stderr xuất hiện như feedback. Claude đọc, hành động, rồi thử dừng lại lần nữa.
- Exit 0 + JSON với
additionalContext: Inject context vào turn tiếp theo mà không chặn. Tốt cho cảnh báo không cần hành động ngay.
Feedback qua additionalContext giới hạn 10,000 ký tự. Nếu output test dài hơn, lọc bớt. HumanLayer đã học bài này: 4,000 dòng tests pass tràn ngập context window và agent mất dấu task. Chỉ hiển thị failures.
Làm sao xây verification loop 3 lớp?
Kết hợp ba hooks trên hai events: PostToolUse command hook cho syntax (Layer 1), Stop command hook cho regression (Layer 3), và Stop prompt hook cho intent (Layer 2). Mỗi lớp chạy tự động. Agent nhận feedback và tự sửa. Đây là một harness engineering example cụ thể, áp dụng Layer 4 trong mô hình harness 5 lớp cho verification thay vì chỉ guardrails.
Layer 1: Verification syntax (PostToolUse)
Chạy sau mỗi lần Write hoặc Edit. Kiểm tra lint và type errors trên file vừa thay đổi. Nhanh, deterministic, không tốn token.
#!/bin/bashINPUT=$(cat)FILE_PATH=$(echo "$INPUT" | jq -r '.tool_input.file_path // empty')
# Bỏ qua file không phải JS/TSif [[ ! "$FILE_PATH" =~ \.(ts|tsx|js|jsx)$ ]]; then exit 0fiGuard clause thoát sớm cho file không phải JS. Phần lint check chạy trên phần còn lại:
# Chạy ESLint trên file đã thay đổi, chỉ hiển thị errorsLINT_OUTPUT=$(npx eslint "$FILE_PATH" --quiet 2>&1)LINT_EXIT=$?
if [ $LINT_EXIT -ne 0 ]; then echo "{\"additionalContext\": \"Lint errors trong $FILE_PATH:\\n$LINT_OUTPUT\"}" exit 0fi
exit 0Chi tiết quan trọng: hook này trả exit 0, không phải exit 2. PostToolUse hooks không thể undo file write. Thay vào đó, trường additionalContext inject lint errors vào turn tiếp theo của Claude. Claude thấy lỗi và tự sửa.
Nuốt output thành công. Chỉ hiển thị failures. Nếu mỗi lần lint pass đều dump output vào context, bạn đang đốt tokens vô ích.
Layer 2: Verification intent (Stop prompt hook)
Chạy khi Claude cố dừng. Hỏi LLM kiểm tra xem request ban đầu đã được giải quyết chưa. Đây là phiên bản Claude Code của PreCompletionChecklistMiddleware từ LangChain.
{ "type": "prompt", "prompt": "Review what was accomplished in this session. Check if all requirements from the user's original request were addressed. If anything is incomplete or missing, respond with {\"decision\": \"block\", \"reason\": \"Incomplete: <what remains>\"}. If everything looks complete, respond with {\"decision\": \"allow\"}."}Với task phức tạp, thay prompt hook bằng agent hook. Agent hooks tạo subagent có thể Read files, Grep codebase, và chạy Bash commands. Kỹ lưỡng hơn, nhưng thêm 2-10 giây.
{ "type": "agent", "prompt": "Verify the work is complete. Read the modified files. Check that the changes match the user's request. Run the test suite. If anything is missing or broken, explain what needs fixing.", "timeout": 120}Layer 3: Verification regression (Stop command hook)
Chạy khi Claude cố dừng. Kiểm tra deterministic: tests có pass không? Build có thành công không?
#!/bin/bashINPUT=$(cat)
# Anti-loop protection, BẮT BUỘCif [ "$(echo "$INPUT" | jq -r '.stop_hook_active')" = "true" ]; then exit 0fi
# Chạy testsTEST_OUTPUT=$(npm test 2>&1)if [ $? -ne 0 ]; then TRIMMED=$(echo "$TEST_OUTPUT" | tail -50) echo "Tests đang fail. Sửa trước khi hoàn thành:\\n$TRIMMED" >&2 exit 2fiNếu tests pass, kiểm tra build:
# Chạy build (tiếp tục verify-regression.sh)BUILD_OUTPUT=$(npm run build 2>&1)if [ $? -ne 0 ]; then TRIMMED=$(echo "$BUILD_OUTPUT" | tail -30) echo "Build đang fail:\\n$TRIMMED" >&2 exit 2fi
exit 0Config đầy đủ
Cả ba lớp trong một .claude/settings.json. PostToolUse hook xử lý syntax (Layer 1):
{ "hooks": { "PostToolUse": [ { "matcher": "Write|Edit", "hooks": [ { "type": "command", "command": "bash .claude/hooks/verify-syntax.sh" } ] } ] }}Stop hooks xử lý regression (Layer 3) và intent (Layer 2), theo thứ tự đó:
{ "hooks": { "Stop": [ { "hooks": [ { "type": "command", "command": "bash .claude/hooks/verify-regression.sh" }, { "type": "prompt", "prompt": "Review what was accomplished. Check if all requirements from the user's original request were addressed. If incomplete, respond with {\"decision\": \"block\", \"reason\": \"<what remains>\"}. If complete, respond with {\"decision\": \"allow\"}." } ] } ] }}Stop hooks chạy theo thứ tự định nghĩa. Đặt command hook nhanh (Layer 3) trước. Nếu tests fail, không cần chạy prompt hook chậm hơn (Layer 2). Command hook chặn, Claude sửa, và chỉ khi tests pass thì prompt hook mới đánh giá intent.
Boris Cherny, người tạo ra Claude Code, cho biết verification feedback loops cải thiện chất lượng đáng kể: “Give Claude a way to verify its work. If Claude has that feedback loop, it will 2-3x the quality of the final result” (X thread, 2026).
Nhận tips Claude Code hàng tuần - Config thực tế, không lý thuyết. Một email mỗi tuần. Đăng ký AI Developer Weekly →
Chi phí chạy verification hooks là bao nhiêu?
Verification hooks thêm khoảng 10-20% token overhead mỗi phiên, chủ yếu từ prompt/agent Stop hooks. Command hooks không tốn token và dưới 5 giây wall time. Nhưng bỏ qua verification tốn nhiều hơn: các team mất trung bình 7 giờ mỗi tuần mỗi engineer cho AI-related inefficiency, và tỷ lệ rework code AI đạt 20-30% khi code AI vượt 40% codebase (Exceeds AI, 2026).
| Không có Verification | Có Verification | |
|---|---|---|
| Token cost mỗi phiên | Baseline | +10-20% |
| Tỷ lệ rework | 20-30% | ~5-10% (ước tính) |
| Thời gian mất mỗi tuần | ~7 giờ | ~2-3 giờ (ước tính) |
| “Xong” có nghĩa là xong | Đôi khi | Gần như luôn luôn |
Các ước tính giảm rework là định hướng, không phải từ nghiên cứu có kiểm soát. Nhưng toán học có lợi cho bạn dù tính thận trọng. Nếu một task fail tốn 30 phút rework, và verification ngăn được một failure mỗi ngày, bạn tiết kiệm 2.5 giờ mỗi tuần với chỉ khoảng 500 tokens thêm mỗi phiên.
Còn có vấn đề nhận thức. Developer cảm thấy nhanh hơn 20% với AI tools nhưng thực tế chậm hơn 19% trên complex tasks (Exceeds AI, 2026). Khoảng cách đó là rework ẩn sau nhận thức năng suất. Verification đóng khoảng cách này bằng cách bắt vấn đề ở bước N thay vì bước N+5.
Bạn không cần cả 3 lớp cùng lúc. Trong các harness engineering best practices, bắt đầu với một layer tốt hơn là plan cả ba. Layer 3 (test-runner Stop hook) là bổ sung có ROI cao nhất. Nó chỉ 15 dòng bash, không tốn token, và bắt failure phổ biến nhất: agent nói “xong” trong khi tests đang hỏng.
Khi nào nên dùng mỗi lớp verification?
Dùng Layer 1 (syntax) luôn. Nó miễn phí, bắt lỗi hiển nhiên, và chạy dưới 2 giây. Dùng Layer 3 (regression) khi project có test suite. Đây là hook đơn lẻ có ROI cao nhất. Dùng Layer 2 (intent) cho task phức tạp hoặc nhiều bước, nơi agent có thể giải quyết sai vấn đề.
| Tình huống | Layer 1 (Syntax) | Layer 2 (Intent) | Layer 3 (Regression) |
|---|---|---|---|
| Prototyping | Có | Không | Không |
| Dev solo, hàng ngày | Có | Không | Có |
| Dự án team | Có | Có (prompt) | Có |
| Hotfix production | Có | Có (agent) | Có |
Cách áp dụng dần:
- Tuần 1: Thêm Stop hook Layer 3 (test runner). Copy script
verify-regression.shở trên. Hook đơn này bắt failure mode phổ biến nhất. - Tuần 2: Thêm PostToolUse hook Layer 1 (syntax). Copy
verify-syntax.sh. Giờ lint errors được tự động sửa thay vì chồng chất. - Khi gặp intent failure: Thêm prompt hook Layer 2. Bạn sẽ biết cần nó khi Claude hoàn thành task mà pass mọi test nhưng không khớp với yêu cầu bạn đặt ra.
Cách này theo phương pháp failure-first: thêm constraint sau failures thực, không phải trước failures tưởng tượng.
Thử ngay:
- Copy
verify-regression.shvào.claude/hooks/- Thêm Stop hook config vào
.claude/settings.json- Làm cho nó executable:
chmod +x .claude/hooks/verify-regression.sh- Yêu cầu Claude thay đổi code, rồi kiểm tra xem Stop hook có chạy khi tests fail không
- Xác nhận agent sửa vấn đề trước khi hoàn thành
Xây dựng harness, không chỉ prompts. Verification là một layer. Hệ thống đầy đủ gồm memory, tools, permissions, và observability. Đăng ký AI Developer Weekly →
FAQ
Self-verification loop trong Claude Code là gì?
Self-verification loop là hệ thống hooks tự động kiểm tra output của Claude Code ở nhiều cấp độ (syntax, intent, regression) trước khi cho phép agent hoàn thành. Nó dùng PostToolUse hooks cho kiểm tra từng file và Stop hooks cho verification hoàn thành task. Agent nhận feedback và tự sửa mà không cần review thủ công. Đây là phiên bản Claude Code của PreCompletionChecklistMiddleware từ LangChain.
Verification có làm chậm Claude Code không?
Command hooks thêm dưới 5ms. Prompt hooks thêm 300-2000ms mỗi Stop event. Agent hooks thêm 2-10 giây. Chúng chạy một lần khi Claude cố dừng, không phải trên mỗi tool call. Overhead này nhỏ so với 7 giờ mỗi tuần các team mất cho AI-related rework (Exceeds AI, 2026).
Stop hook trong Claude Code là gì?
Stop hook chạy mỗi khi Claude kết thúc phản hồi. Exit code 2 chặn Claude dừng lại và bắt buộc nó tiếp tục với feedback từ stderr. Trường stop_hook_active ngăn loop vô hạn bằng cách báo hiệu khi Claude đang ở trạng thái forced-continuation. Nó hỗ trợ 4 loại handler: command, prompt, agent, và http (Claude Code docs).
Làm sao ngăn loop vô hạn trong verification hooks?
Luôn kiểm tra trường stop_hook_active trong Stop hook. Khi giá trị là true, Claude đang ở trạng thái forced-continuation từ lần chặn trước. Trả về exit 0 để cho nó dừng. Không có kiểm tra này, hook chặn mọi lần cố dừng vô thời hạn, tạo loop vô hạn đốt tokens cho đến khi phiên hết thời gian.
Harness engineering là gì?
Harness engineering là kỷ luật xây dựng constraints, tools, feedback loops, và observability quanh AI agent để nó hoạt động ổn định trong production. Công thức: Agent = Model + Harness. Self-verification loops là một harness engineering example. Model giữ nguyên, hệ thống quanh nó cải thiện kết quả. Để hiểu framework đầy đủ, đọc Harness Engineering: Hệ Thống Quanh AI Quan Trọng Hơn AI.
Đọc Tiếp
- Harness Engineering: Hệ Thống Quanh AI Quan Trọng Hơn AI - Framework giải thích tại sao verification quan trọng, với dữ liệu benchmark LangChain và tổng quan harness 5 lớp.
- Chọn Hook Nào Cho Claude Code? Hướng Dẫn Quyết Định - So sánh 4 loại handler với decision tree. Dùng bài này để chọn giữa command, prompt, agent, và http hooks cho các lớp verification.
- Nghịch Lý Ràng Buộc: Ít Tự Do AI Hơn, Code Tốt Hơn - Tại sao thêm constraint như verification loops thực sự cải thiện output của agent, với ba nguồn dữ liệu độc lập làm bằng chứng.