TL;DR - Claude Code’s Stop hook blocks the agent from finishing until verification passes. Combine it with PostToolUse feedback injection to build a 3-layer verification loop (syntax, intent, regression) in 20 minutes. Jump to the full setup →
📊 What this post builds:
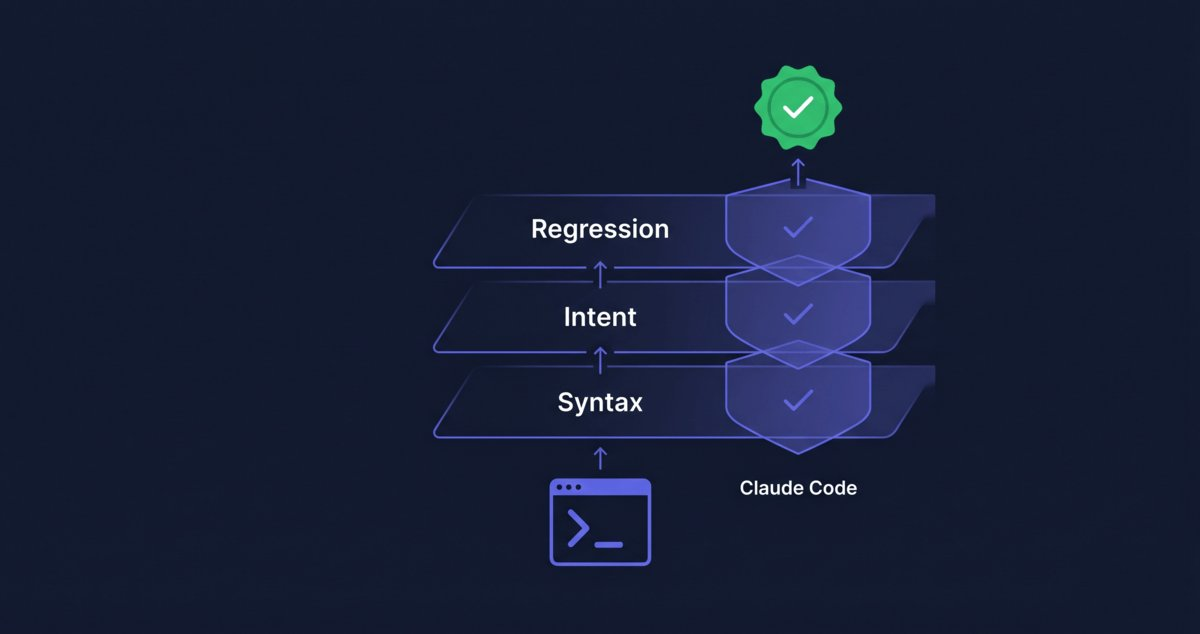
- A 3-layer verification system using 2 hook events and 3 handler types
- Copy-paste Stop hook with anti-loop protection (
stop_hook_active)- Complete
.claude/settings.jsonconfig combining all layers- ROI breakdown: verification costs tokens, skipping it costs 7 hours/week
Two hook setups. Same Claude Code session. Different outcomes:
# What most devs have: a formatting hook# PostToolUse: runs prettier after file editsjq -r '.tool_input.file_path' | xargs npx prettier --write
# What this post builds: a verification loop# PostToolUse: checks syntax on every file change# Stop: blocks completion until tests pass + intent verified# Result: agent can't say "done" until it actually isThe first catches formatting. The second catches logic errors, missed requirements, and broken tests before the agent claims it’s finished.
LangChain’s PreCompletionChecklistMiddleware is the most documented example of this pattern. It contributed to a 13.7-point benchmark gain using harness changes alone. This post builds the Claude Code equivalent using hooks. For where this verification loop fits in the larger Claude Code stack, see our complete Claude Code guide.
What does “verification” actually mean for an AI coding agent?
Verification means checking that the agent’s output matches the task’s intent, not just that the code compiles. Only 3% of developers report high trust in AI-generated code (Qodo, State of AI Code Quality, 2025). Most developers stop at syntax checks (lint, format, type-check). Production verification needs two more layers.
Three verification layers, each catching a different class of failure:
| Layer | Checks | Catches | Misses | Hook |
|---|---|---|---|---|
| 1. Syntax | Code compiles, formats | Typos, type errors | Logic bugs | PostToolUse command |
| 2. Intent | Output matches request | Wrong approach, missing features | Regressions | Stop prompt/agent |
| 3. Regression | Existing tests pass | Broken functionality, side effects | Untested requirements | Stop command |
“Run the tests” only covers Layer 3. Tests verify what you wrote tests for, not what you asked the agent to do. If you asked Claude to add pagination and it added sorting instead, every test still passes. Layer 2 catches that.
Spotify’s Honk system demonstrates this at scale: 1,500+ PRs merged through verification loops, handling roughly 50% of all PRs automatically (Spotify Engineering, Dec 2025). Their key design choice: the agent doesn’t know how verification works. It just gets pass/fail feedback. That separation keeps the agent focused on the task, not on gaming the verifier.
How does Claude Code’s Stop hook work?
The Stop hook fires every time Claude finishes responding. Exit code 2 blocks Claude from stopping and forces it to continue working. This single mechanism prevents the agent from saying “done” when it isn’t (Claude Code docs). Four handler types are available for Stop hooks. For a full comparison, see the Hook Decision Guide.
Here’s the critical part most tutorials skip: the stop_hook_active field.
#!/bin/bashINPUT=$(cat)
# CRITICAL: prevent infinite verification loops# When true, Claude is already in a forced-continuation stateif [ "$(echo "$INPUT" | jq -r '.stop_hook_active')" = "true" ]; then exit 0 # Let Claude stop — don't loop foreverfi
# Run tests — block stop if they failnpm test 2>&1 || { echo "Tests failing. Fix before completing." >&2 exit 2}
exit 0Without checking stop_hook_active, the hook blocks every stop attempt. Claude fixes the tests, tries to stop, gets blocked again, fixes more, tries to stop, gets blocked again. Infinite loop. Always check this field.
The Stop hook input JSON looks like this:
{ "session_id": "abc123", "transcript_path": "/path/to/transcript.jsonl", "cwd": "/your/project", "hook_event_name": "Stop", "stop_hook_active": false}Two ways to send feedback back to the model:
- Exit 2 + stderr: The stderr message appears as feedback. Claude reads it, acts on it, then tries to stop again.
- Exit 0 + JSON with
additionalContext: Inject context into the agent’s next turn without blocking. Good for warnings that don’t require immediate action.
Feedback via additionalContext is capped at 10,000 characters. If your test output is longer, filter it. HumanLayer learned this the hard way: 4,000 lines of passing tests flooded the context window and the agent lost track of the task. Surface failures only.
How do you build a 3-layer verification loop?
Compose three hooks across two events: a PostToolUse command hook for syntax (Layer 1), a Stop command hook for regression (Layer 3), and a Stop prompt hook for intent (Layer 2). Each runs automatically. The agent gets feedback and self-corrects. This is a concrete harness engineering example, applying Layer 4 of the 5-layer harness to verification instead of just guardrails.
Layer 1: Syntax verification (PostToolUse)
Runs after every Write or Edit tool call. Checks lint and type errors on the changed file. Fast, deterministic, zero tokens.
#!/bin/bashINPUT=$(cat)FILE_PATH=$(echo "$INPUT" | jq -r '.tool_input.file_path // empty')
# Skip non-JS/TS filesif [[ ! "$FILE_PATH" =~ \.(ts|tsx|js|jsx)$ ]]; then exit 0fiThe guard clause exits early for non-JS files. The lint check runs on everything else:
# Run ESLint on the changed file, surface errors onlyLINT_OUTPUT=$(npx eslint "$FILE_PATH" --quiet 2>&1)LINT_EXIT=$?
if [ $LINT_EXIT -ne 0 ]; then echo "{\"additionalContext\": \"Lint errors in $FILE_PATH:\\n$LINT_OUTPUT\"}" exit 0fi
exit 0The key detail: this hook returns exit 0, not exit 2. PostToolUse hooks can’t undo the file write. Instead, the additionalContext field injects the lint errors into Claude’s next turn. Claude sees the errors and fixes them on its own.
Swallow success output. Only surface failures. If every passing lint check dumps output into context, you’re burning tokens on noise.
Layer 2: Intent verification (Stop prompt hook)
Runs when Claude tries to stop. Asks an LLM to check whether the original request was actually addressed. This is the Claude Code equivalent of LangChain’s PreCompletionChecklistMiddleware.
{ "type": "prompt", "prompt": "Review what was accomplished in this session. Check if all requirements from the user's original request were addressed. If anything is incomplete or missing, respond with {\"decision\": \"block\", \"reason\": \"Incomplete: <what remains>\"}. If everything looks complete, respond with {\"decision\": \"allow\"}."}For complex tasks, swap the prompt hook for an agent hook. Agent hooks spawn a subagent that can Read files, Grep the codebase, and run Bash commands. More thorough, but adds 2-10 seconds.
{ "type": "agent", "prompt": "Verify the work is complete. Read the modified files. Check that the changes match the user's request. Run the test suite. If anything is missing or broken, explain what needs fixing.", "timeout": 120}Layer 3: Regression verification (Stop command hook)
Runs when Claude tries to stop. Deterministic check: do the tests pass? Does the build succeed?
#!/bin/bashINPUT=$(cat)
# Anti-loop protection, MANDATORYif [ "$(echo "$INPUT" | jq -r '.stop_hook_active')" = "true" ]; then exit 0fi
# Run testsTEST_OUTPUT=$(npm test 2>&1)if [ $? -ne 0 ]; then TRIMMED=$(echo "$TEST_OUTPUT" | tail -50) echo "Tests failing. Fix before completing:\\n$TRIMMED" >&2 exit 2fiIf tests pass, check the build too:
# Run build (continuation of verify-regression.sh)BUILD_OUTPUT=$(npm run build 2>&1)if [ $? -ne 0 ]; then TRIMMED=$(echo "$BUILD_OUTPUT" | tail -30) echo "Build failing:\\n$TRIMMED" >&2 exit 2fi
exit 0The complete configuration
All three layers in one .claude/settings.json. The PostToolUse hook handles syntax (Layer 1):
{ "hooks": { "PostToolUse": [ { "matcher": "Write|Edit", "hooks": [ { "type": "command", "command": "bash .claude/hooks/verify-syntax.sh" } ] } ] }}The Stop hooks handle regression (Layer 3) and intent (Layer 2), in that order:
{ "hooks": { "Stop": [ { "hooks": [ { "type": "command", "command": "bash .claude/hooks/verify-regression.sh" }, { "type": "prompt", "prompt": "Review what was accomplished. Check if all requirements from the user's original request were addressed. If incomplete, respond with {\"decision\": \"block\", \"reason\": \"<what remains>\"}. If complete, respond with {\"decision\": \"allow\"}." } ] } ] }}Stop hooks run in definition order. Put the fast command hook (Layer 3) first. If tests fail, there’s no point running the slower prompt hook (Layer 2). The command hook blocks, Claude fixes, and only when tests pass does the prompt hook evaluate intent.
Boris Cherny, creator of Claude Code, reports that verification feedback loops improve quality 2-3x: “Give Claude a way to verify its work. If Claude has that feedback loop, it will 2-3x the quality of the final result” (X thread, 2026).
Get weekly Claude Code tips - Real configs, not theory. One email per week. Subscribe to AI Developer Weekly →
What’s the cost of running verification hooks?
Verification hooks add roughly 10-20% token overhead per session, primarily from the prompt/agent Stop hooks. Command hooks cost zero tokens and under 5 seconds of wall time. But skipping verification costs significantly more: teams lose an average of 7 hours per week per engineer to AI-related inefficiency, and AI code rework rates hit 20-30% when AI-generated code exceeds 40% of the codebase (Exceeds AI, 2026).
| Without Verification | With Verification | |
|---|---|---|
| Token cost per session | Baseline | +10-20% |
| Rework rate | 20-30% | ~5-10% (estimated) |
| Time lost per week | ~7 hours | ~2-3 hours (estimated) |
| “Done” means done | Sometimes | Almost always |
The rework reduction estimates are directional, not from a controlled study. But the math works in your favor even conservatively. If a failed task costs 30 minutes of rework, and verification prevents one failure per day, you save 2.5 hours per week for roughly 500 extra tokens per session.
There’s also a perception problem. Developers perceive +20% speed from AI tools but experience -19% actual speed on complex tasks (Exceeds AI, 2026). That gap is rework hiding behind perceived productivity. Verification closes it by catching problems at step N instead of step N+5.
You don’t need all 3 layers at once. Among harness engineering best practices, starting with one layer beats planning all three. Layer 3 alone (the test-runner Stop hook) is the highest-ROI single addition. It’s 15 lines of bash, costs zero tokens, and catches the most common failure: the agent says “done” while tests are broken.
When should you use each verification layer?
Use Layer 1 (syntax) always. It’s free, catches the obvious, and runs in under 2 seconds. Use Layer 3 (regression) when your project has a test suite. It’s the highest-ROI single hook. Use Layer 2 (intent) for complex or multi-step tasks where the agent might solve the wrong problem entirely.
| Scenario | Layer 1 (Syntax) | Layer 2 (Intent) | Layer 3 (Regression) |
|---|---|---|---|
| Prototyping | Yes | No | No |
| Solo dev, daily work | Yes | No | Yes |
| Team project | Yes | Yes (prompt) | Yes |
| Production hotfix | Yes | Yes (agent) | Yes |
How to adopt gradually:
- Week 1: Add the Layer 3 Stop hook (test runner). Copy the
verify-regression.shscript above. This single hook catches the most common failure mode. - Week 2: Add the Layer 1 PostToolUse hook (syntax). Copy
verify-syntax.sh. Now lint errors get fixed automatically instead of piling up. - When you hit an intent failure: Add the Layer 2 prompt hook. You’ll know you need it when Claude completes a task that passes all tests but doesn’t match what you asked for.
This follows the failure-first method: add constraints after real failures, not before imagined ones.
Try it now:
- Copy
verify-regression.shinto.claude/hooks/- Add the Stop hook config to your
.claude/settings.json- Make it executable:
chmod +x .claude/hooks/verify-regression.sh- Ask Claude to make a code change, then check if the Stop hook fires when tests fail
- Confirm the agent fixes the issue before completing
Build your harness, not just your prompts. Verification is one layer. The full system includes memory, tools, permissions, and observability. Subscribe to AI Developer Weekly →
FAQ
What is a self-verification loop in Claude Code?
A self-verification loop is a system of hooks that automatically checks Claude Code’s output at multiple levels (syntax, intent, regression) before allowing the agent to finish. It uses PostToolUse hooks for per-file checks and Stop hooks for task-completion verification. The agent receives feedback and self-corrects without manual review. This is the Claude Code equivalent of LangChain’s PreCompletionChecklistMiddleware.
Does verification slow down Claude Code?
Command hooks add under 5ms. Prompt hooks add 300-2000ms per Stop event. Agent hooks add 2-10 seconds. These fire once when Claude tries to stop, not on every tool call. The overhead is minimal compared to the 7 hours per week teams lose to AI-related rework (Exceeds AI, 2026).
What is the Stop hook in Claude Code?
The Stop hook fires every time Claude finishes responding. Exit code 2 blocks Claude from stopping and forces it to continue with feedback from stderr. The stop_hook_active field prevents infinite loops by signaling when Claude is already in a forced-continuation state. It supports 4 handler types: command, prompt, agent, and http (Claude Code docs).
How do I prevent infinite loops in verification hooks?
Always check the stop_hook_active field in your Stop hook. When the value is true, Claude is already in a forced-continuation state from a previous block. Return exit 0 to let it stop. Without this check, the hook blocks every stop attempt indefinitely, creating an infinite loop that burns tokens until the session times out.
What is harness engineering?
Harness engineering is the discipline of building constraints, tools, feedback loops, and observability around an AI agent to make it reliable in production. The formula: Agent = Model + Harness. Self-verification loops are one harness engineering example. The model stays the same; the system around it improves results. For the full framework, see Harness Engineering: The System Around AI Matters More Than AI.
What to Read Next
- Harness Engineering: The System Around AI Matters More Than AI - The framework that explains why verification matters, with the LangChain benchmark data and a 5-layer harness overview.
- Which Claude Code Hook Do You Need? A Decision Guide - The 4 handler types compared with a decision tree. Use this to decide between command, prompt, agent, and http hooks for your verification layers.
- The Constraint Paradox: Less AI Freedom, Better Code - Why adding constraints like verification loops actually improves agent output, with three independent data points as evidence.